TP Link
1. 아키텍처 개요
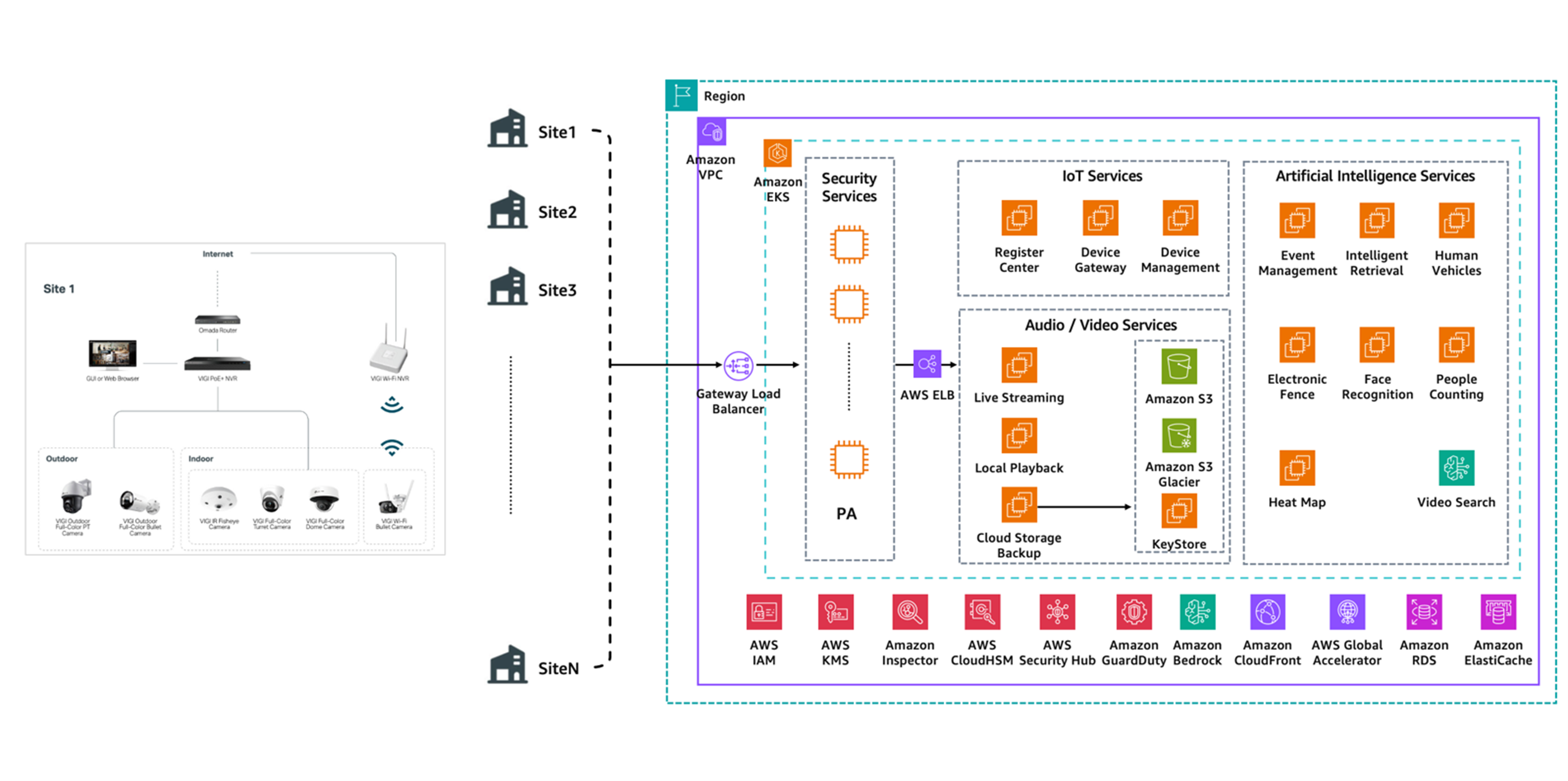
TP-Link는 170개국 이상에 제품을 판매하는 글로벌 네트워킹·스마트홈 기업으로, 기존의 소비자용 보안 서비스를 넘어 기업용 영상 보안·클라우드 저장 서비스로 확장하기 위해 AWS 기반 인프라를 전면 재구성했습니다. 핵심 목표는 감시 영상의 near-zero loss, 카메라부터 재생까지 전 구간 암호화, 국가별 데이터 주권 규제 대응, 수만 개 사이트의 24시간 고동시성 업로드 처리입니다.
TP-Link는 우리가 자주 쓰는 공유기, 소비자용 IoT 보안 카메라와 네트워크 장비로 잘 알려진 기업으로, 2012년부터 AWS와 협력해왔습니다. 이번 재구성은 기존 소비자 서비스에서 기업 고객(슈퍼마켓, 창고, 산업단지 등)으로 시장을 확장하는 과정에서 이루어졌습니다. 소비자 서비스와 달리 기업 고객은 영상 한 클립이라도 손실되면 안 된다는 기준을 요구하고, GDPR 같은 국가별 데이터 주권 규제도 동시에 충족해야 했습니다.
이 아키텍처에서 특이한 점은 두 가지입니다. 첫째, Gateway Load Balancer + Palo Alto 차세대 방화벽 조합입니다. AWS 네이티브 보안 서비스만 쓰는 일반적인 구조와 달리 AWS Marketplace를 통해 서드파티 보안 장비를 인라인으로 끼워넣었습니다. 둘째, KMS와 CloudHSM을 함께 사용합니다. 단순 키 관리를 넘어 하드웨어 수준의 키 보증이 필요한 기업 보안 요건이 반영된 것으로 보입니다.
2. 아키텍처 분석
CloudFront + Global Accelerator
이 두 서비스는 얼핏 비슷해 보이지만 역할이 다릅니다. CloudFront는 엣지 노드에서 콘텐츠를 캐싱·배포하는 CDN이라 저장된 영상을 재생하는 다운링크에 적합합니다. 반면 Global Accelerator는 캐싱 없이 TCP/UDP 트래픽을 AWS 내부 백본망으로 라우팅하는 서비스로, 카메라에서 클라우드로 올라오는 실시간 업로드처럼 지연에 민감한 업링크 트래픽에 더 맞습니다.
공식 문서에서 언급한 QUIC 프로토콜 기반 멀티패스 중복 전송도 이 계층에서 동작합니다. QUIC은 UDP 기반이라 TCP 대비 핸드쉐이크가 빠르고 패킷 손실 시 재전송이 효율적입니다. 단일 네트워크 경로가 끊겨도 다른 경로로 전송이 이어지기 때문에 영상 클립 손실을 막을 수 있습니다.
흐름으로 정리하면 업링크는 Global Accelerator → AWS 백본 → VPC, 저장된 영상 재생(다운링크)은 CloudFront 엣지 → 클라이언트 방향으로 분리됩니다.
Gateway Load Balancer + Palo Alto NGFW
공식 문서에는 "Palo Alto 차세대 방화벽을 AWS Marketplace를 통해 도입해 국가 간 트래픽을 탐지하고 악성 공격을 방어한다"고만 나옵니다. 다이어그램 기준으로 보면 Gateway Load Balancer(GWLB)와 함께 구성된 구조입니다.
ALB나 NLB는 타겟 그룹이 서버로 지정되어 있어 중간에 방화벽을 삽입하려면 라우팅 구조를 전부 변경해야 합니다. 반면 GWLB는 L3에서 동작해 출발지/목적지 IP를 바꾸지 않으면서 트래픽을 방화벽으로 투명하게 우회시킨 뒤 검사가 끝나면 원래 경로로 돌려보냅니다. 애플리케이션 코드나 라우팅 구성 변경 없이 네트워크 경로 중간에 Palo Alto를 끼워넣을 수 있고, 단순 포트 차단이 아니라 트래픽 내용 분석과 악성 패턴 탐지 수준의 제어가 가능합니다. (GWLB 뒤에 나오는 PA가 팔로알토 방화벽 서비스들)
Amazon EKS
다이어그램 기준으로 보면 IoT Services, Audio/Video Services, AI Services 전체가 EKS 위에서 동작하는 구조입니다. 공식 문서에 EKS 직접 언급은 없습니다. 수만 개 사이트에서 올라오는 트래픽을 처리하면서 IoT, 영상 처리, AI 분석처럼 성격이 다른 워크로드를 함께 운영하려면 컨테이너 오케스트레이션이 필요합니다. EKS를 선택했을 때의 장점은 각 도메인 서비스를 독립적인 마이크로서비스로 배포·확장할 수 있고, IAM IRSA(서비스 어카운트 기반 IAM 권한), VPC CNI(파드 레벨 VPC 네트워킹), ELB 자동 연동 같은 AWS 네이티브 통합이 자연스럽다는 점입니다.
IoT Services (Register Center / Device Gateway / Device Management)
다이어그램에서 확인한 레이어로, Register Center / Device Gateway / Device Management 세 컴포넌트로 구성됩니다. 공식 문서에 세부 동작 방식은 나오지 않습니다. 이름과 일반적인 IoT 플랫폼 구조를 기준으로 보면, Register Center는 카메라·게이트웨이 장비를 최초 등록하고 인증하는 역할, Device Gateway는 등록된 디바이스와 클라우드 간 실시간 통신을 중계하는 허브, Device Management는 디바이스 상태 모니터링과 원격 설정 관리를 담당하는 것으로 추정됩니다. IoT 환경에서 이 세 기능은 거의 필수적으로 분리되는 구성입니다. 실제로 어떤 프로토콜을 사용하고 내부적으로 어떻게 구현됐는지는 문서에 나와있지 않습니다.
그렇지만 흐름을 유추해보자면, Site1~SiteN의 카메라들이 클라우드에 처음 접속할 때 Register Center를 통해 인증받고, 이후 영상 데이터는 Device Gateway → ELB → Audio/Video Services 경로로 흐르는 구조로 예상할 수 있습니다.
Audio/Video Services
Live Streaming / Local Playback / Cloud Storage Backup 세 기능으로 나뉩니다. 공식 문서에서 직접 언급된 내용은 다음과 같습니다. - 카메라가 이상 이벤트를 자동 감지해 영상 클립을 클라우드로 전송합니다 - 로컬 SD 카드와 클라우드에 이중 저장(dual-copy)합니다
현장 네트워크가 끊겨도 SD 카드에 1차 보존이 되고, 반대로 현장 장비가 손상되거나 분실돼도 이미 클라우드 복사본을 확보하겠다는 것입니다. - Live Streaming을 통해 실시간 영상 스트림을 클라우드에서 수신하고 처리하고, Local Playback으로 현장 NVR에 저장된 영상을 클라우드에서 원격으로 접근 혹은 SD카드에 저장된 영상을 로컬에서 직접 재생하거나, Cloud Storage Backup으로 이상 이벤트 감지 시 영상 클립을 자동으로 Amazon S3에 업로드하는 구조라고 분석할 수 있습니다.
Cloud Storage Backup에서 S3로 저장된 영상은 KMS/CloudHSM 기반 KeyStore를 통해 암호화되고, 보관 기간이 지난 데이터는 S3 Glacier로 자동 이전될 수 있습니다.
Artificial Intelligence Services
Event Management, Intelligent Retrieval, Human Vehicles, Electronic Fence, Face Recognition, People Counting, Heat Map, Video Search 8가지 AI 기능이 있습니다.
다이어그램에 Amazon Bedrock이 포함되어 있어 일부 AI 추론이 Bedrock 기반일 가능성이 있지만, 공식 문서에 구체적인 언급은 없습니다. 기능 구성을 보면 단순 저장 및 재생을 넘어 영상 자체를 분석해 이벤트를 감지하고 나중에 검색 가능하게 만드는 것이 이 레이어의 목적으로 보입니다.(Video Search) Cloud Storage Backup에서 S3에 저장된 영상이 AI Services로 넘어가 분석되고, 이상 이벤트가 Event Management로 전달되는 흐름으로 보입니다.
Amazon KMS + AWS CloudHSM
공식 문서에는 KMS만 명시되어 있지만, 다이어그램 하단에 CloudHSM이 나란히 등장합니다. KMS는 AWS가 관리하는 소프트웨어 기반 키 관리 서비스이고, CloudHSM은 전용 하드웨어 보안 모듈입니다. - CloudHSM은 전용 하드웨어 장치(HSM)을 사용하여 AWS에서 사용할 수 있는 암호화 키를 생성하고 직접 관리합니다. - HSM 사용 시 애플리케이션에서 암호화 키가 필요할 경우, 애플리케이션 측에서 다루는 게 아니라, HSM이라는 전용 장치에서 암호화 키를 생성 및 관리합니다. - HSM에 들어 있는 정보(키)는 외부에 복사 및 재생성이 되지 않으며 고도의 보안이 필요한 환경에서 사용합니다.
둘을 함께 쓰는 패턴은 일반 데이터 암호화 키는 KMS로 관리하고, 마스터 키처럼 가장 중요한 키는 물리적으로 격리된 CloudHSM에 보관하는 이중 계층 구조를 예상할 수 있습니다.
Amazon Inspector + AWS Security Hub + Amazon GuardDuty
Inspector는 EKS 위에서 돌아가는 컨테이너 이미지와 워크로드를 지속적으로 스캔해 취약점과 의도치 않은 네트워크 노출을 탐지합니다. - 구체적으로 설명하자면, ECR에 올라간 컨테이너 이미지를 이미지 푸시 시점과 주기적으로 스캔해서 CVE(알려진 취약점) 데이터베이스와 대조합니다. 패키지 버전이 오래됐거나 패치가 안 된 라이브러리가 있으면 심각도(Critical, High, Medium)와 함께 리포트를 올립니다. - 또한 네트워크 노출 분석으로, 보안 그룹, 라우팅 테이블, 네트워크 ACL을 분석해서 의도치 않게 인터넷에 열려있는 포트나 경로가 있는지 자동으로 탐지합니다.
GuardDuty는 CloudTrail 로그, VPC Flow Logs, DNS 쿼리를 분석해 비정상 API 호출, 내부자 위협, 크립토마이닝 시도 같은 런타임 위협을 ML 기반으로 탐지합니다. - 구체적으로 설명하자면 Inspector가 정적인 취약점을 보는 반면, GuardDuty는 실제로 일어나고 있는 일을 봅니다. 분석하는 데이터 소스는 CloudTrail(API 호출 기록), VPC Flow Logs(네트워크 트래픽), DNS 쿼리, EKS 감사 로그입니다. 여기서 ML 기반으로 이상 패턴을 탐지합니다. - 평소에 없던 리전에서 S3 버킷에 대량 접근이 발생하거나, 루트 계정으로 갑자기 로그인하는 비정상 API 호출이나 특정 IAM 역할이 평소와 다른 시간대, 다른 IP에서 대량의 데이터를 다운로드하는 내부자 위협 등을 탐지하는 것이 중요할 것입니다.
Security Hub는 Inspector와 GuardDuty를 포함한 여러 보안 서비스의 결과를 한 곳에서 집계하고 우선순위를 정리합니다. - 단순 취합이 아니라 CVSS 점수 기반으로 심각도를 정규화하고 우선순위를 매기기 때문에, 운영팀이 지금 당장 뭘 먼저 봐야 하는가를 한 화면에서 판단할 수 있다는 장점이 있습니다. - 또한 EventBridge와 연동하면 특정 심각도 이상의 Finding이 들어왔을 때 Lambda를 트리거해서 자동 대응까지 연결할 수 있다고 합니다.
Amazon S3 + S3 Glacier
S3 버킷을 국가 및 지역 단위로 분리해 데이터 현지화 요건(ex: EU - GDPR)을 충족합니다. 특정 국가의 영상 데이터가 해당 국가 리전의 버킷에만 저장되도록 구성하면 GDPR 같은 데이터 주권 규제를 아키텍처 수준에서 강제할 수 있습니다. S3의 높은 처리량과 탄력적 확장성 덕분에 수만 개 카메라가 동시에 쓰기를 해도 데이터 손실 없이 처리됩니다. 장기 보관이 필요한 영상은 S3 Lifecycle 정책을 통해 Glacier로 자동 이전되어 비용을 최적화합니다.
Amazon RDS + Amazon ElastiCache
영상 메타데이터(디바이스 정보, 이벤트 로그, 사용자 접근 기록 등)를 RDS에 저장하고, 빈번하게 조회되는 데이터나 세션 정보는 ElastiCache로 캐싱하는 구조로 보입니다.
3. 보완점
감사 로그
Inspector, Security Hub, GuardDuty 조합으로 보안 모니터링은 갖췄지만, CloudTrail, VPC Flow Logs, S3 Access Logs 같은 감사 로그 체계가 아키텍처에 드러나지 않습니다. 수만 개 디바이스에서 데이터가 올라오고 국가별로 버킷이 분리된 구조라면, 데이터 무단 열람이나 리전 간 비정상 접근을 탐지하기 위한 중앙 로그 집계 파이프라인이 필요합니다. 기업용 보안 인프라에서 감사 로그가 빠지면 사고 발생 후 원인 추적이 어렵습니다. 당연한 것이기에 고의적으로 뺀 것일까요??
멀티리전 구조에서의 장애 대응
S3 멀티리전 배치로 현지화 저장은 해결했지만, 특정 리전 장애 시 서비스 연속성을 어떻게 보장하는지가 아키텍처에 나오지 않습니다. 24시간 near-zero loss를 목표로 하는 서비스라면 Cross-Region Replication이나 리전 간 자동 페일오버 구조가 명시적으로 포함되어야 합니다. 현재 문서만 보면 단일 리전 장애 시 해당 리전 사용자의 데이터 접근이 어떻게 유지되는지 알 수 없습니다.
디바이스 인증 체계
Register Center에서 카메라를 등록 및 인증한다고 설명하지만, 수만 대 디바이스 중 하나가 악의적으로 위조되거나 탈취됐을 때에는 어떻게 해야 할까요?? IoT 환경에서 디바이스 자체가 공격 벡터가 되는 일이 꽤나 빈번할 것 같은데, 디바이스별 격리된 환경과 침해된 디바이스를 개별 차단할 수 있는 구조가 없다면, 디바이스 하나가 침해됐을 때 영향이 전체로 퍼질 수 있다고 생각합니다.
개인정보 문제
Face Recognition, People Counting 같은 AI 분석을 보면 생체정보를 직접 다루는 것을 알 수 있습니다. 이 데이터가 분석 과정에서 어떻게 격리되고, GDPR 기준 생체정보 처리 제한 같은 국가별 규제에 맞게 처리되는지 아키텍처에 반영이 없는 것으로 보입니다. AI 분석 파이프라인이 S3의 원본 영상에 직접 접근하는 구조라면 분석 데이터의 국경 간 이동 문제가 생길 수 있고, 분석 목적별로 데이터 접근 경계를 분리하는 구조가 필요하다고 생각합니다.