AWS 인프라 분석 - Security Response Automation
개요
AWS에서는 보안 이벤트를 신속하게 감지하고 대응하기 위한 자동화를 권장합니다. 자동화는 감지 및 대응 속도를 높이고 워크로드 증가에 따라 보안 운영을 확장하는 데 도움이 됩니다.
보안 대응 자동화란?
"특정 조건이나 이벤트를 기반으로 애플리케이션이나 리소스를 원하는 상태로 되돌리기 위해 미리 계획된 프로그램 방식의 조치"입니다.
NIST 사이버 보안 프레임워크
- Identify: AWS 환경의 리소스, 애플리케이션, 데이터를 파악합니다.
- Protect: 적절한 통제 및 보안 장치를 구현합니다.
- Detect: 사이버 보안 이벤트 발생을 식별하는 활동을 구현합니다.
- Automate: 이벤트 기반으로 원하는 상태를 달성하는 계획된 프로그램을 구현합니다.
- Investigate: 보안 이벤트의 근본 원인을 체계적으로 분석합니다.
- Respond: 감지된 보안 이벤트에 대해 자동 혹은 수동으로 조치를 수행합니다.
- Recover: 보안 이벤트로 인해 손상된 기능 혹은 서비스를 복구합니다.
아키텍처 분석
자동화 복구 흐름 (3단계)

AWS에서의 자동화 복구는 탐지(Detection) → 오케스트레이션(Orchestration) → 복구(Remediation) 단계로 구성됩니다.
핵심 서비스
- AWS CloudTrail / AWS Config: 사용자 활동 및 리소스 구성 변경 로그를 수집합니다.
- Amazon EventBridge: 이벤트 기반으로 자동화를 트리거하는 단일 서비스입니다.
- Amazon GuardDuty: 비정상적인 활동을 탐지합니다.
- AWS Security Hub: 보안 서비스의 발견 사항들을 통합하여 상관 분석을 진행합니다.
자동화 대응 예시
- VPC 보안 그룹 수정
- EC2 인스턴스 보안 패치
- 자격 증명 교체
- AWS WAF IP 차단 목록 추가
대응 자동화 설계 방법
자동화 설계 목표는 정량적이어야 합니다.
- 서버에 대한 원격 관리 네트워크 접근은 제한되어야 합니다.
- 서버 스토리지 볼륨은 암호화되어야 합니다.
- AWS 콘솔 로그인은 MFA로 보호되어야 합니다.
자동화 시나리오: CloudTrail 비활성화 자동 복구
CloudTrail 로깅은 모든 AWS 계정과 리전에 활성화되어야 합니다. 비활성화되면 자동으로 재활성화하고 보안 운영팀에게 알림을 발송합니다.
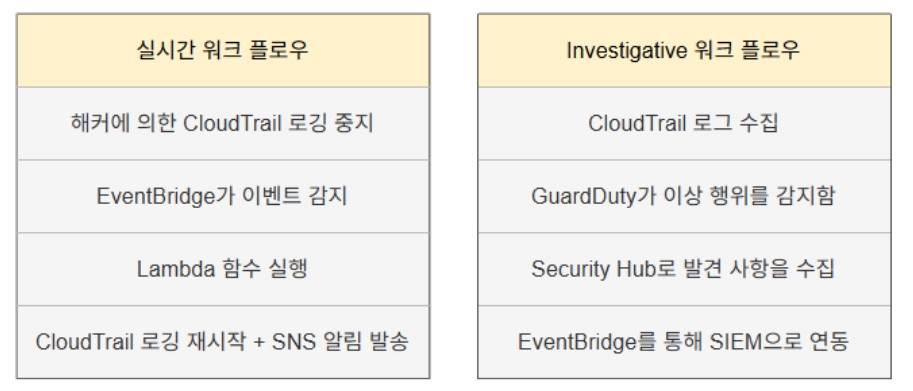
Lambda 코드 핵심 로직
1. Finding에서 TrailARN 추출
trailARN = event['detail']['findings'][0]['ProductFields']['action/awsApiCallAction/affectedResources/AWS::CloudTrail::Trail']
2. 보안팀에게 SNS 알림 발송
3. CloudTrail 로깅 재활성화
아키텍처 구성 요소
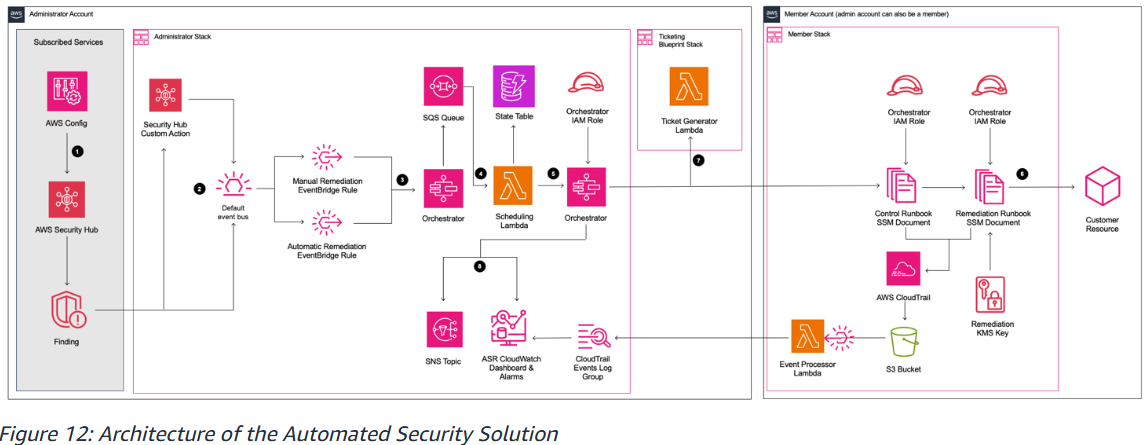
Administrator Account
탐지 흐름
- ① AWS Config → AWS Security Hub → Finding 생성
- ② Security Hub Custom Action(수동) 또는 Automatic Remediation EventBridge Rule(자동)을 통해 트리거합니다.
③④⑤ 오케스트레이션 흐름
- Orchestrator Lambda → SQS Queue → Scheduling Lambda → State Table(DynamoDB) → Orchestrator
⑧ 로깅 및 모니터링
- CloudTrail Events Log Group → ASR CloudWatch Dashboard & Alarm → SNS Topic
Ticketing Blueprint Stack
⑦ Finding 발생 시 외부 티켓 시스템으로 자동 티켓을 생성합니다. (보안 이벤트 추적 및 처리 기록 관리)
Member Account
⑥ 복구 실행 흐름
- Orchestrator IAM Role → Control Runbook SSM Document(검증) → Remediation Runbook SSM Document(실행) → Customer Resource
- Remediation KMS Key를 통해 복구 작업 시 암호화를 보장합니다.
보안 관점 분석
한계점
1. 오탐 대응 미흡
자동화 복구 실행 후 실제로는 정상적인 배포 작업이 서비스 장애를 야기할 수 있습니다. 현재 위협 탐지 후 Finding 발생 시 맥락 파악 없이 바로 실행되어 정상 작업과 실제 공격을 구분하는 로직이 부재합니다.
2. 멀티 계정 환경에서의 권한 복잡도
여러 계정이 있을 때 각 계정마다 IAM Role을 부여해야 하는데, Orchestrator에서의 권한 관리가 복잡해집니다.
3. SQS 병목 가능성
SQS → Scheduling Lambda가 순차적으로 처리되므로, 대규모 공격 시 중요도가 높은 Finding이 큐에서 밀릴 수 있습니다. 우선순위 기반 처리 로직이 부재합니다.
4. SSM Document 버전 관리 위험
Remediation Runbook이 SSM Document로 관리되는데, 잘못된 버전이 배포되면 복구 로직 자체가 오작동될 수 있습니다.
5. 단일 리전 한계
아키텍처가 특정 리전 중심으로 설계되어, 멀티 리전 환경에서 Finding을 중앙으로 모으는 구성이 추가적으로 필요합니다.
6. 복구 후 검증 부재
Remediation Runbook 실행 후 실제로 복구가 잘 됐는지 확인하는 절차가 없습니다. 복구 실행 후 정상 상태 복귀 여부를 검증하는 피드백 루프가 부재합니다.
개선 권고 사항
1. 오탐 방지를 위한 맥락 기반 판단 추가
배포 스케줄, 변경 관리 시스템과 연동하고 AWS Config의 변경 타임라인과 비교하여 오탐을 방지할 수 있습니다.

2. IAM 권한 최소화 자동화
수동으로 관리되는 각 Member Account IAM Role을 AWS Organizations와 SCP를 이용하여 중앙에서 일괄 관리하고, 계정 추가 시 자동으로 최소 권한이 적용되도록 합니다.
3. Finding 우선순위 기반 처리
SQS 단일 큐 대신 Critical, High, Low Finding으로 나눠 심각도별 별도 큐를 구성합니다.
4. 멀티 리전 대응
각 리전의 Security Hub에서 집계 리전을 설정하고(Security Hub의 Cross-Region Aggregation 기능), 중앙 Administrator Account에서 통합 처리합니다.
5. 복구 후 자동 검증 추가
Step Functions로 대기 후 AWS Config로 현재 상태를 재확인하고, 정상이면 티켓을 닫고 비정상이면 재시도 또는 관리자 에스컬레이션을 진행합니다.
[참고자료]
https://aws.amazon.com/ko/blogs/security/how-get-started-security-response-automation-aws/